여는 글
현재 명지대학교 입학처 입학관리팀 홈페이지에 직접 올라가,
모집요강, 입시결과 등 입시 관련 문서 기반 답변을 해줄 rag-llm 챗봇 서비스를 개발하고 있다.
무려 2024.06.30~09.27일까지.... 이 기간동안 엄청나게 많은 트러블 슈팅을 하며, 존재하는 대부분의 pdf파싱 라이브러리를 다 써보고 조합도 해보며 그럼에도 불구하고 실패했었는데, llm관련 컨퍼런스 및 영상까지 찾아보며 드디어 pdf 파싱에 있어 챗봇 프로젝트에 매우 적합한 솔루션을 찾을 수 있었고,
추가적으로 목차 기반 메타데이터를 뽑아 이를 직접 파싱된 페이지에 삽입하는 전처리 방법을 수많은 테스트 끝에 찾아내며,,,
챗봇의 답변 퀄리티가 아주 많이 상승하였다.
너무나도 감사하고, 너무나도 다행이다..
이 챗봇의 퀄리티를 올리지 못한다면 ai팀인 나 때문에, 팀원 모두가 손해를 볼 수 있었던 상황이라..
해결된 지금의 순간이 너무 감사하다...
어떻게 이 챗봇의 답변 퀄리티를 크게 상승할 수 있었는지, 목차 기반 메타데이터로 데이터에 전처리 작업을 어떻게 했는지,
지금까지 어떤 과정을 거쳤는지 다시 한번 돌아보는 글을 작성해볼 것이다.
2024.06.30~0909일 까지의 트러블 슈팅 & 수많은 도전








=> 작업을 늘 노션에다 기록하면서 진행중이다.
위 보이는 모든 과정들이 06.30~09.27일 동안의 도전과정이고,,
이렇게 모아보면 별거 아닌 것처럼 보이겠지만, 저 작은 토글에 도전 방법, 진행방법, 결과, 코드 까지 모든 부분을 다 기록하며 진행했다.
토글 하나당 짧으면 1~2시간, 길면 하루~이틀,,,, 정말로 엄청나게 많은 시간을 쏟아부었다.
결국엔 솔루션을 찾았다.
PDF 파싱 솔루션
LLM모델-RAG 방식 챗봇 - pdf 문서 파싱
포커스 - 중요한 것은...RAG 방식으로 LLM 챗봇을 만들 때 가장 중요하다고 생각하는 부분은 바로 문서의 파싱, 임베딩 과정이다.지금 개발해야할 부분은 입학관리팀에서 진행하던 입시생분들의
choiet.tistory.com
0717~0720개발일지 html & pdf에서 표 데이터 전처리 과정
여는 글포스팅 글이 늦어졌는데, 너무 오랜 시간 다양한 도전을 하다가 글을 쓸 타이밍을 놓쳐버렸다.이 글에서 간단하게 17~20일 동안 마루에그 프로젝트의 필수 사항인 데이터 전처리 과정을
choiet.tistory.com
=> 내가 이전에 작성한 챗봇 개발기인데, 보다시피 문제는 "표데이터 파싱문제"이다.
pdftotree, tabula, poppler, pdfplumber, PyMuPDF 등 이외에도 수많은 라이브러리를 사용했으나,
절대로 표 데이터 만큼은 훌룡하게 파싱이 불가능하다.
복합행이 있는 경우는 완전히 깨지기 마련이다.
이를 해결할 수 있는 방법을 llm관련 컨퍼런스 영상을 통해 찾게 되었다.

=> 해답은 MD형식 기반으로 파일을 파싱할 수 있는 "PyMuPDF4LLM"라이브러리 였다.
PyMuPDF4LLM은 PDF 문서를 Markdown 형식으로 변환하여 대형 언어 모델(LLM) 및 검색 기반 생성(RAG) 애플리케이션에서 활용할 수 있도록 설계된 라이브러리고 -> PyMuPDF를 기반으로 하며, 문서의 구조와 형식을 유지하면서 텍스트, 이미지, 표 등을 효율적으로 추출할 수 있다.
가장 큰 이점이 바로 Markdown 기반으로 변환이 된다는 점이다. -> 데이터 파싱 결과가, 의미가 매우 명확함

=> PyMuPDF4LLM의 결과물이다. 타 라이브러리 대비 의미가 명확하며, 표 데이터 역시 "|"기호를 덧붙여 여러개를 쓰며 복합행의 경우의 그 의미를 파악하고 구조적으로 명확하게 계산하여 작성한다.(복합행의 정도에 따라 계산하여 "|"기호를 적절히 여러개 더 계산함)
목차 기반 메타데이터로 데이터에 전처리 작업
또한 pdf파싱에서 PyMuPDF4LLM을 통해 표 데이터 문제를 해결했으나 여전히 방대한 pdf에서 자료를 검색하는데 성능이 저하되는것을 막긴 어려웠기에 효과적인 rag-llm검색 성능을 향상시키기 위해 목차의 데이터를 가져와 이를 데이터에 삽입해주는
전처리 작업을 구상하여 적용해봤는데, 결과는 매우 훌룡... 성공적이였다.
문제 상황을 먼저 보자면,,
대학 입시 관련 PDF 문서(모집요강, 입시결과 등)를 파싱하여 챗봇이 질문에 정확하게 답변할 수 있도록 하는 시스템을 개발하는 과정에서 여러 문제점이 있는데 아래 3개와 같다.
- PDF 내 정보가 너무 많고 복잡하여 챗봇이 정확한 답변을 찾기 어려움
- 전형별 정보가 혼합되어 질문과 무관한 내용을 답변에 포함하는 경우가 많음
- 표 형태의 정보는 텍스트로 변환 시 의미가 왜곡되는 경우가 있었음
위 문제의 개선의 핵심은 PDF 문서의 목차 정보를 활용하여 각 페이지에 적절한 메타데이터를 추가하는 것이였다.
그 주요 단계를 설명하자면 아래와 같다.
1. 목차 페이지 자동 탐색
PDF 문서에서 "CONTENTS"라는 단어가 포함된 페이지를 찾아 목차 페이지로 지정한다.
contentPage = None
for idx, page in enumerate(output):
text = page['text']
if "CONTENTS" in text:
contentPage = idx + 1
output[idx]['metadata']['title'] = "CONTENTS"
break
2. 목차에서 제목과 페이지 번호 추출
목차 페이지에서 각 항목의 제목과 페이지 번호를 정규표현식을 사용하여 추출한다.
toc_mapping = {}
pageGap = 2 # PDF 내부 페이지와 메타데이터 페이지 간의 갭
for line in toc_lines:
clean_line = re.sub(r"[^\w\s]", "", line)
clean_line = clean_line.strip()
match = re.search(r"(.*?)\s+(\d+)$", clean_line)
if match:
title = match.group(1).strip()
start_page = int(match.group(2).strip()) + pageGap
toc_mapping[start_page] = title
(여기서 pageGap은 PDF의 내부 페이지 번호와 실제 순서 간의 차이를 보정하기 위한 값임)
3. 페이지에 메타데이터 추가
추출한 목차 정보를 기반으로 각 페이지에 해당하는 제목(전형명)을 메타데이터로 추가한다.
for idx, page in enumerate(output):
current_page = idx + 1
metadata = page['metadata']
for start_page in sorted(toc_mapping.keys()):
if current_page >= start_page:
next_page_start = min([p for p in toc_mapping.keys() if p > start_page], default=None)
if next_page_start is None or current_page < next_page_start:
metadata['title'] = toc_mapping[start_page]
break
4. 메타데이터를 텍스트에 통합
각 페이지의 텍스트 앞에 해당 페이지의 메타데이터(전형명)를 명시적으로 추가하여 문맥을 강화한다.
title = metadata.get('title', '')
if title:
text = f"**{title} 문서입니다. - 중요! 이 문서 전체는 {title}에 해당하는 정보입니다.**\n\n" + text
text = f"**{title}**\n" + text
성능 향상의 원리를 다시 한번 간략 설명하자면 아래와 같다.
1. 문맥 인식 강화
각 페이지의 텍스트에 해당 전형명을 명시적으로 추가함으로써, 텍스트 임베딩 과정에서 문맥 정보가 함께 인코딩된다.
이를 통해 챗봇은 "특성화고등졸재직자전형"과 같은 전형명이 질문에 포함되면 해당 전형과 관련된 정보만을 정확하게 검색할 수 있게 된다.
2. 정보 구조화
목차 정보를 활용하여 PDF 문서의 구조를 이해함으로써, 각 페이지가 어떤 주제나 전형에 속하는지 명확히 구분할 수 있게 되었다.
이걸로 검색 과정에서 관련성 높은 정보를 우선적으로 찾아내는 데 큰 도움이 되는 역할을 한것같다.
3. 메타데이터 기반 검색 개선
메타데이터가 풍부해짐에 따라 벡터 검색 과정에서 관련성 판단의 정확도가 높아졌다. 예를 들어, "만학도전형"에 대한 질문이 들어오면 메타데이터에 "만학도전형"이 포함된 페이지가 우선적으로 검색된다. -> 원래는 데이터가 너무 많다보니 쓸데없는 데이터 기반 답변했음.. 그러니 퀄리티가 낮을 수 밖에..
위와 같이 pymupdf4llm & 목차 기반 메타데이터 삽입 접근 방식을 통해 아래와 같은 뚜렷한 개선을 확인할 수 있었다.
정확도 향상 -> 챗봇이 특정 전형에 관한 질문에 대해 해당 전형에 대한 정보만을 정확하게 제공하게 되었음
관련성 개선 -> 불필요한 정보를 배제하고 질문과 직접적으로 관련된 내용만을 답변에 포함시키게 되었음
문맥 이해 향상 -> 챗봇이 문서의 구조를 이해하고 있어, 전체 문서의 맥락 속에서 보다 의미 있는 답변을 제공할 수 있게 되었음
[결과] 이를 통해 어떻게 되었나..
목차 기반 메타데이터 삽입 접근 방식을 통해 얻은 이점 + PDF파싱 고도화 작업을 통한 이점


예시를 들어 설명해보겠다. pdf모집요강을 보면 위와같이 농어촌학생전형에 대한 설명으로 2페이지에 걸쳐 설명하고 있다.
첫번째 페이지는 타이틀에 "학생부종합(농어촌학생전형)"이라 명시되어있으니 rag기반 문서검색을 잘 해낼 것이다.
하지만 두번째 페이지를 보라, 이어서 농어촌학생전형에 대한 중요한 설명을 하고 있지만 "농어촌학생전형"이라는 문맥이 존재하지 않다보니, rag기반 검색에서 우선순위로 검색되지 않는다.
모든 모집요강 데이터는 위와 같이 긴 문맥을 형성하고 있기에, 질문에 대한 완벽한 검색이 이뤄지지 않고 그에 따라 답변 퀄리티가 낮아질 수밖에 없던것...

=> 따라서 아까 위 코드기반 설명을 했듯이 목차기반으로 메타데이터를 생성하고 이를 페이지에 직접 삽입해주는 방법으로 전처리 자동화를 구축했고,

=> 아까 예시로 든 농어촌학생전형의 2번째 페이지는 위와 같이 db에 저장될때 **무슨무슨 전형**이라는 메타데이터가 자동으로 삽입되어 들어가있는 것을 볼 수 있다. 모든 페이지에 위와 같이 메타데이터가 삽입될 수 있도록 파싱 기능을 구현해둔 상태이다.
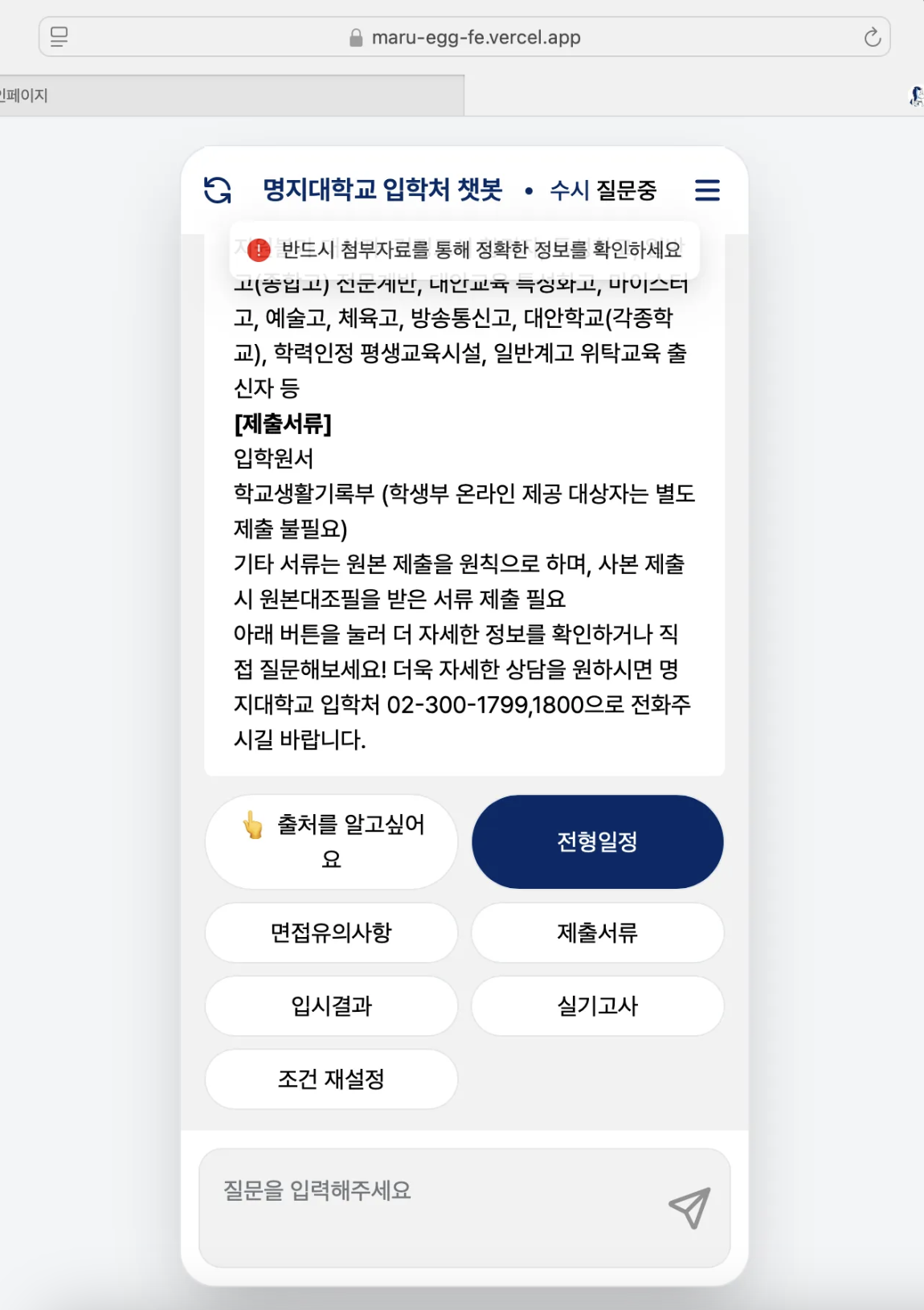
=> 결과적으론, 위와 같이 문맥이 끊어지는 긴 정보의 모집요강 내용이라도 농어촌학생전형 2번째 페이지정보를 완벽하게 가지고와 설명하는 것을 볼 수 있다.
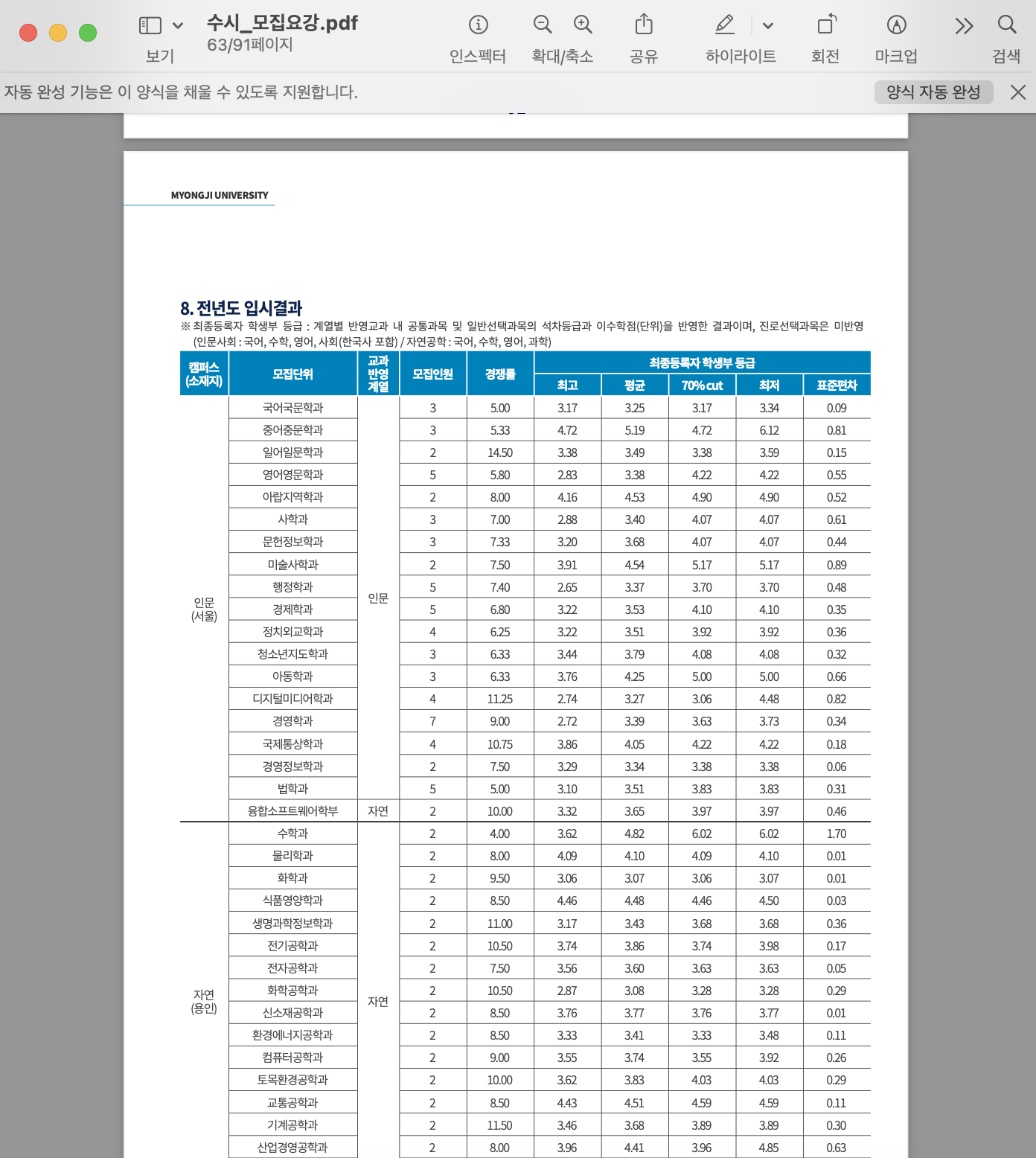
=> 뿐만 아니라, 이 입시결과는 농어촌학생전형의 입시결과인데 그 어디에도 이 입시결과 페이지가 농어촌학생전형임을 알 수 없는데도 불구하고,,,


=> 어떠한 실수 없이, 완벽하게 문서를 검색하여 표 데이터를 기반으로 오차없는 답변을 할 수 있게 되었다.
마무리 하며,
2024.06.30~09.27일까지 수십번의 트러블 슈팅, 수십번의 도전 끝에 해냈다.
테스트 결과 표기반 100% 정확도로 오차없이 답변이 가능하며,
90p 가 넘는 pdf를 기반으로 해도 문맥을 고려한 메타데이터 삽입 전처리 방식으로
완벽하게 관련 문서만을 검색하여 답변하도록 하여, 챗봇의 답변 퀄리티를 아주 크게 올릴 수 있었다.
힘들고 고되었으나, 아주 뿌듯하다..
너무나도 많이 배운 프로젝트가 되었으며, 식견이 넓어진 마루에그 프로젝트에 감사하다.
이제 명지대학교 입학처 홈페이지에 우리가 개발한 서비스가 올라가게 되고, 많은 입시생들, 부모님들이 사용하게 된다.
다 끝났다고 손놓지 말고, 긴장 풀리지 않게 조절하고
이후 유지보수와 개선에 집중해야할듯하다.
'Project > 명지대학교-입학관리팀챗봇-MARU_EGG' 카테고리의 다른 글
| 명지대학교 입학관리팀 홈페이지에 챗봇 서비스 오픈 - 11/22일 목 (0) | 2024.11.24 |
|---|---|
| 창의적 SW프로그램 경진대회 - MARU_EGG 최우수상 입상 (2) | 2024.09.06 |
| 입학관리팀챗봇 서비스 maru_egg 서비스 대회 제출 및 발표 (1) | 2024.08.22 |
| 야무지게 views 분리한거 & 코드 정리 & camelot 재도전 + rag-llm전체 고도화 작업 (0) | 2024.08.17 |
| maru-egg 프로젝트 개발일지 - APIs 개선 & crontab으로 ec2에서 파일 파싱 자동화 스크립트 작성 & 스왑진행 & 도메인, https적용 & swagger오류 해결 (1) | 2024.08.11 |



