여는 글
현재 진행하고 있는 입학관리팀 챗봇 서비스 구현에서 ask_question_api -> rag-llm기반 질의응답 api에 대해 추가 작업을 요청하였다.
관련하여 llm모델이 참고한 문서에 대한 위치로 바로 하이퍼링킹할 수 있는 링크 데이터와 참조 문서의 반환이 필요했고
pdf 페이지를 바로 렌더링 할 수 있어야 했다. -> 이 부분은 따로 정리해서 블로그로 추가작성함
이 과정을 간략하게 설명해보겠다.
이전의 방식

=> 이전에는 ask_question_api를 주어진 데이터 양식에 맞게 호출을 하면 다음과 같이 questionType, questionCategory, 그 질의 응답으로 answer만 리턴하였는데 추가로 이 rag-llm모델이 답변을 생성할 때 참조했던 db의 문서 데이터들과 그 문서 데이터가 원 pdf의 몇페이지에 저장되었는지, 그리고 그 참고한 문서로 바로 이동할 수 있는 이동 링크를 반환해야 했다.
수정한 방식
그렇기에 이전에 단순 문서를 스플릿하여 저장하던 방식에서 현재 page기반 몇 페이지인지의 데이터도 함께 저장하도록 db구조를 변경하였고, 추가로 파일이 업로드될 때 기본적으로 media특정 위치에 저장될 수 있게 하였으며, pdf로 바로 하이퍼링킹을 할 수 있게 관련 코드 작성을 진행했다.

=> 간단하게만 코드를 뜯어서 본다면 이와 같은 구조이다.
참조한 문서 정보에서 title, page정보를 가져오고 title이 곧 media루트 경로에 저장된 파싱대상이였던 파일 이름이기에 이를 기반으로 link 데이터를 만들어낸다. 이를 기반 리턴할 references에 넣어준다.
=> (base_url은 현재 개발환경과 프로덕션환경을 분리해두었기에 다음과 같은 설정으로 기본 위치를 변경시켜주었다.)
결과
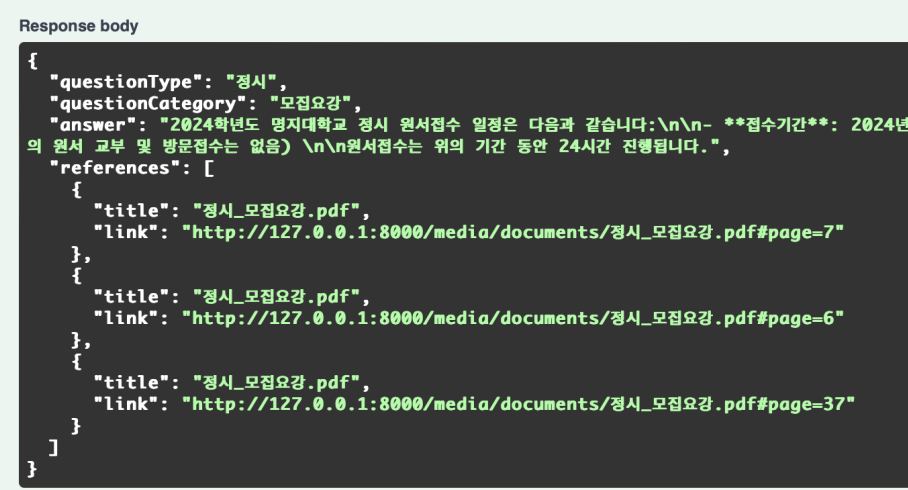
=> 결과를 보면 참고한 문서에 대한 위치를 정확히 파악해서 해당 링크까지 생성하고!

=> 링크로 이동하면 정확하게 해당 문서가 있는 pdf로 이동한다!
결론 및 느낀점
이전 표기반 데이터 전처리 관련해서 너무 고생했는데, 이번 task의 경우 큰 오류없이 원활하게
해결되어서 다행이였다. 또 진행하면서 재미있었다. pdf라는 포맷의 자유로움이 좋았으며
이런 기능을 기반으로 pdf관련 다양한 서비스를 만들어 볼 수 있겠다는 생각이 들었다.
앞으로 해야할 과제는 표기반 데이터 전처리 문제와, llm모델이 참고문서 이외의 확장적인 답변을 하지 않도록
체인 설정을 진행하는 것이다.
프로젝트가 거의 막바지에 다다랐는데, 추가적인 문제발생 없이 task들 잘 마무리하고 잘 끝냈으면 좋겠다.
'Project > 명지대학교-입학관리팀챗봇-MARU_EGG' 카테고리의 다른 글
| 야무지게 views 분리한거 & 코드 정리 & camelot 재도전 + rag-llm전체 고도화 작업 (0) | 2024.08.17 |
|---|---|
| maru-egg 프로젝트 개발일지 - APIs 개선 & crontab으로 ec2에서 파일 파싱 자동화 스크립트 작성 & 스왑진행 & 도메인, https적용 & swagger오류 해결 (1) | 2024.08.11 |
| 0717~0720개발일지 html & pdf에서 표 데이터 전처리 과정 (1) | 2024.07.24 |
| 입학관리팀챗봇 개발일지 - 모델 버전으로 llm api개발, 프론트와의 cors오류 해결, delete & retrieve APIs 개발 (2) | 2024.07.18 |
| DJango에서 Swagger로 파일 업로드 진행하는 방법 + api 2차 완성 (1) | 2024.07.12 |



